Network Infrastructure Management
Network infrastructure management keeps switches, firewalls, wireless, internet circuits, and internal traffic working together so staff can stay productive, data can move securely, and outages are less likely to spread into expensive business interruptions.
At 8:12 a.m., Aimee Y.‘s accounting firm lost phones, line-of-business access, and VPN connectivity when a misconfigured core switch created a broadcast storm across flat network segments; twelve staff sat idle for most of the day, and the disruption cost $56,000.
This story is based on a real business technology support pattern: the kind of operational breakdown that often becomes visible only after systems, staff, vendors, and workflows are already under strain. Names, dates, timelines, and identifying details have been anonymized or modified for confidentiality, while preserving the practical lessons behind the scenario.


About the Author: Scott Morris
Scott Morris is an experienced IT and cybersecurity professional with 16 years of hands-on experience in managed technology services. He specializes in Network Infrastructure Management and has spent his career building practical recovery, security, and operational continuity processes for businesses across Nevada.
This article reflects the operating perspective of Scott Morris, a managed IT and cybersecurity professional who helps businesses maintain, secure, document, and recover business technology environments. Scott Morris has 16+ years of managed IT and cybersecurity experience. His work is grounded in practical risk reduction, business continuity, secure infrastructure management, recovery readiness, and operational resilience, including support for Reno and Sparks business environments where network stability, access control, and downtime prevention directly affect operations.
This article explains common operational patterns, controls, and warning signs so decision-makers can evaluate network management quality more clearly. This is general technical information; specific network environments and compliance obligations change strategy.
Network infrastructure management is the disciplined oversight of the systems that move and control traffic inside and outside the business: switches, firewalls, wireless platforms, internet circuits, DNS, DHCP, remote access, and the rules that determine who can reach what. A common failure point is treating these pieces as isolated hardware purchases instead of one managed system with ownership, documentation, monitoring, change control, and recovery plans.
- Availability: Stable routing, resilient internet connectivity, and healthy switching prevent phones, cloud applications, printers, and line-of-business systems from failing together.
- Security boundary: Firewalls, segmentation, VPN controls, and administrative access settings limit how far an attacker or malware event can move.
- Change control: Firmware updates, rule changes, circuit cutovers, and hardware swaps need documented review because many outages are introduced during rushed maintenance.
Network management overlaps with server and cloud operations because applications often appear broken when the real issue is DNS failure, routing drift, or a firewall rule change. It also connects to hybrid infrastructure oversight, where on-premises equipment, cloud services, and site connectivity must be understood as one environment. In regulated offices, including medical practices reviewing HIPAA requirements, segmentation and access control affect both uptime and the protection of sensitive information.
What does network infrastructure management actually include?

It includes asset inventory, network diagrams, firewall rule review, switch and wireless configuration management, circuit oversight, firmware lifecycle tracking, VPN administration, segmentation design, performance monitoring, and administrative access control. In mature environments, it also includes configuration backups, change records, and clear ownership for each device and circuit. What usually separates a stable environment from a fragile one is not the brand of hardware; it is whether the business can explain how traffic flows, who can change it, and how it is recovered after a failure.
Why does network infrastructure management affect uptime, security, and cost?
The network is a shared dependency, so one weak point can interrupt many services at once. A failed uplink, expired VPN certificate, overloaded wireless controller, or careless firewall change can stop phones, cloud applications, printing, warehouse scanning, and remote work in the same hour. Security exposure grows for the same reason: if the network is flat, poorly segmented, or administered through shared accounts, a compromised device can move laterally far more easily, turning a contained problem into a wider operational event.
How does competent network infrastructure management work in practice?
Competent teams start with accurate device inventory, current diagrams, named administrative accounts, backed-up configurations, and monitoring for interface errors, latency, circuit status, VPN health, and hardware thresholds. They review changes before implementation, schedule maintenance windows, validate results after the change, and keep rollback steps available if the network behaves unexpectedly. During a routine review, a series of WAN latency alerts may look like a carrier problem, but experienced teams check switch logs and interface counters first; it is common to discover a closet uplink negotiating incorrectly after a hardware swap, causing packet loss that only affects voice and remote desktop traffic. Guidance in NIST SP 800-207 Zero Trust Architecture matters here because internal network location should not be treated as automatic trust; segmentation and continuous verification reduce the business impact when one account or device is compromised.
What evidence shows a network is being managed properly?
A mature environment should produce observable evidence, not verbal reassurance. That usually includes a current asset inventory, a diagram showing VLANs and uplinks, timestamped configuration backups, firmware status reports, alert escalation records, administrative login logs, and documented change history for firewall and switching updates. One of the first things experienced IT teams check is whether alerts are tied to ownership and review cadence, because monitoring without response records often means problems were seen but not acted on. Authentication guidance in NIST SP 800-63B exists for a practical reason: user identity is often the real perimeter, so network devices should be administered through individual accounts, stronger authentication where supported, and reviewable logs rather than shared credentials passed around informally.
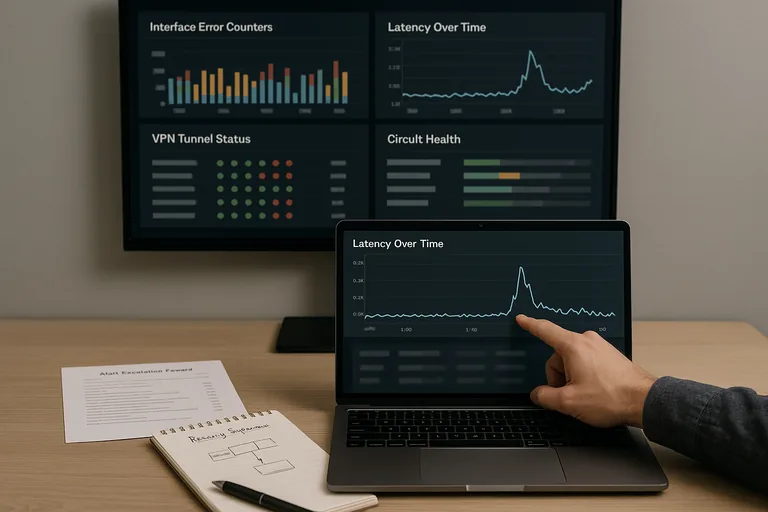
What should a business owner ask before trusting a provider or internal team?
- Documentation: Can they show a current diagram, device inventory, circuit list, and configuration backup process, or is the network understood only from memory?
- Monitoring ownership: Who receives firewall, switch, internet, and VPN alerts, how quickly are they reviewed, and what escalation path exists after hours?
- Access control: Are network devices managed with named admin accounts, removed promptly when staff change roles, and reviewed on a defined schedule?
- Change discipline: Is there a record of recent rule changes, firmware updates, and rollback planning, especially for core equipment?
- Resilience testing: Have they tested failover, remote access, and controller recovery recently, or is recovery capability assumed rather than verified?